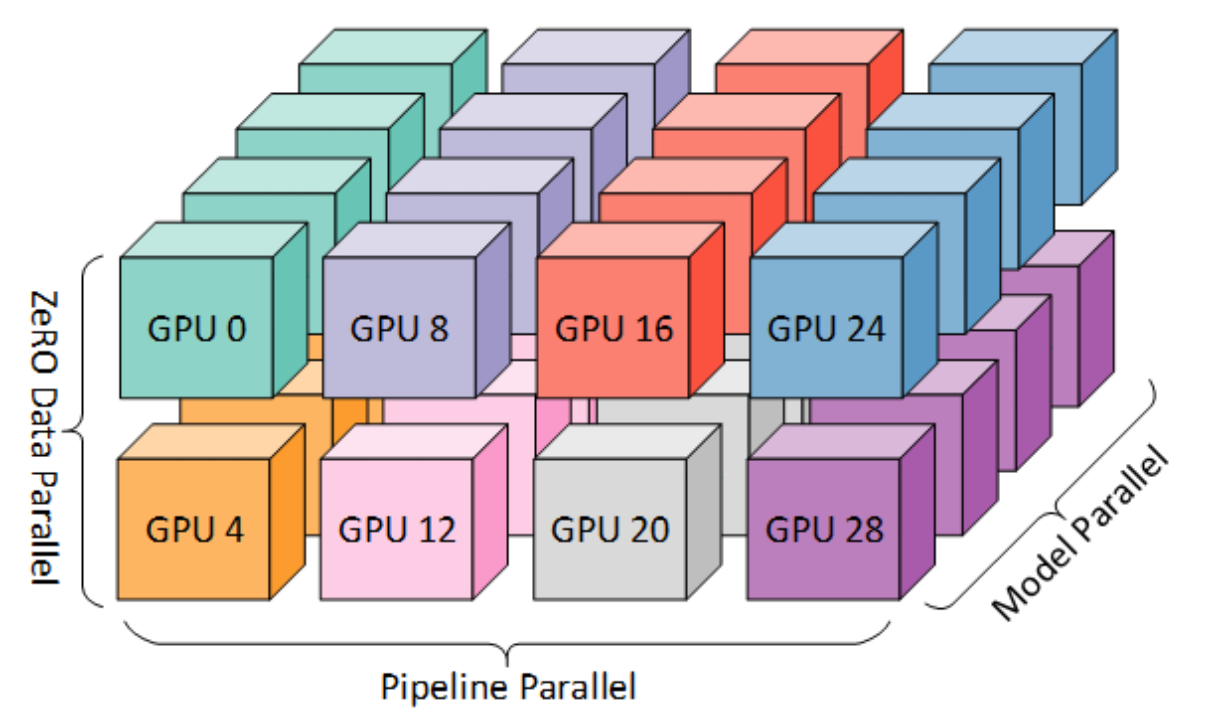
3 parallelism dimensions are used to get a very high model throughput:
- Tensor Parallelism: 4 (each tensor is split up into multiple chunks processed
separately and in parallel on different GPUs)
- Pipeline Parallelism: 12 (the model is split up vertically (layer-level)
across multiple GPUs)
- Data Parallelism: 8 (the model is replicated multiple times, each replica
being fed a slice of the data)
Code and training setup
The final code for the model
can be found on
GitHub, as well as
the training setup.
It uses
PyTorch-1.11 w/ CUDA-11.5,
DeepSpeed 0.6.0 and
NVIDIA’s apex@master.
Configuration
To find the best configuration, many possible topologies and configurations for
models of sizes ranging between 150B and 200B parameters were investigated to test
throughput, iteration speed and memory usage. A detailed map of the tested configurations
can be found here.
Discussions
All the discussions leading to the selected topology have been documented along the
way
by Stas in his chronicles.
Throughput
The initial throughput was around 90 TFLOPs and over the next few weeks we were able to
improve it all the way to 150 TFLOPs after experimenting with multiple combinations of
TP/PP/DP/MBS and NHIDDEN/NHEADS/NLAYERS settings, taking into account the best dimension
multipliers according to
NVIDIA tile quantization guidelines (matrix dimensions need to
be divisible by 128).
Somewhere halfway through this process the JeanZay engineers improved the cluster’s
network which gave an additional performance boost.
Towards the end an additional speed up was achieved by layer rebalancing which gave
the tied embedding matrices a similar weight to transformer blocks,
which made all
the GPUs equally loaded in terms of memory as explained here.
While working on this, we switched from an
estimated TFLOPs calculation
to
the exact one which is slightly higher.
According to the NVIDIA and Deepspeed LLM training experts 150 TFLOPs is pretty
much the highest throughput one can achieve with A100 80GB gpus give or take a few
TFLOPs for this size of the model. A larger model would have an even higher throughput.
For more information on the design choices of the model,
take a look at the accompanying blog post by Julien Launay.