Scaling laws
First, we derived scaling laws, giving us an upper-bound on the "optimal" model with our compute: that's ~392B parameters trained for ~165B tokens (more on that budget later). But scaling laws don't account for serving/inference costs, downstream task performance, etc.
In addition, we need to make sure low resource languages still get enough tokens seen during pretraining. We don't want our model to have to zero-shot entire languages, do we? So, we decided that we should at least pretrain for 300-400B tokens.

Compute
Then, we went back to our budget: 18 weeks on 384 A100 80GB provided to us by GENCI on the French supercomputer Jean Zay, that's 1,161,261 A100-hours! We estimated how many tokens would that allow us to train on for different model sizes, across wide "safety margins" to accommodate hurdles. We had a clear winner: a ~175B model gives us a good shot at perhaps even reaching a bit over 400B tokens.

Taking shape
Now, to decide on a shape. Well first, we had a sneaky look at how other big 100B+ parameter models were shaped. We also did a bit of reading, and found some really cool work on how the shape of models should change with increased scale: specifically Kaplan et al. (2020) (a classic!), and Levine et al. (2020) (big models are too fit! make them chunkier!).
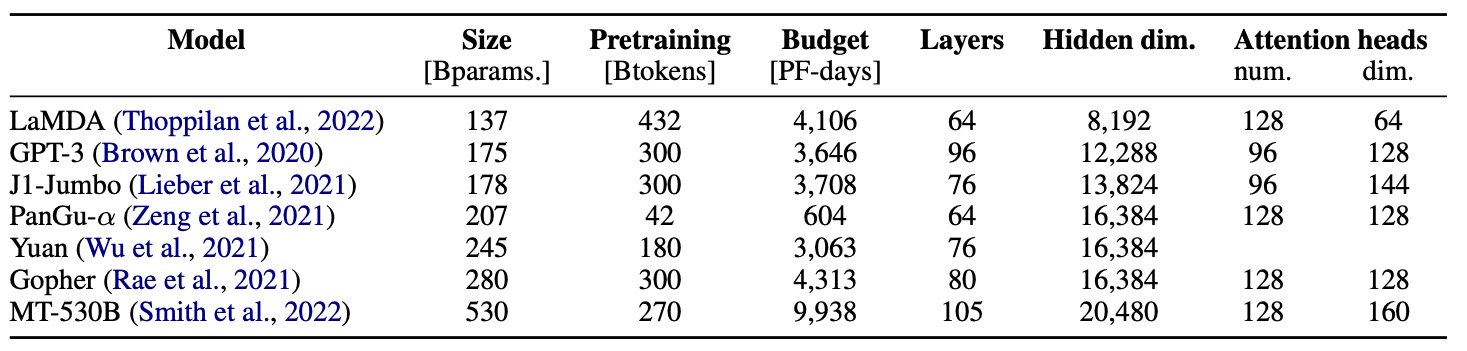
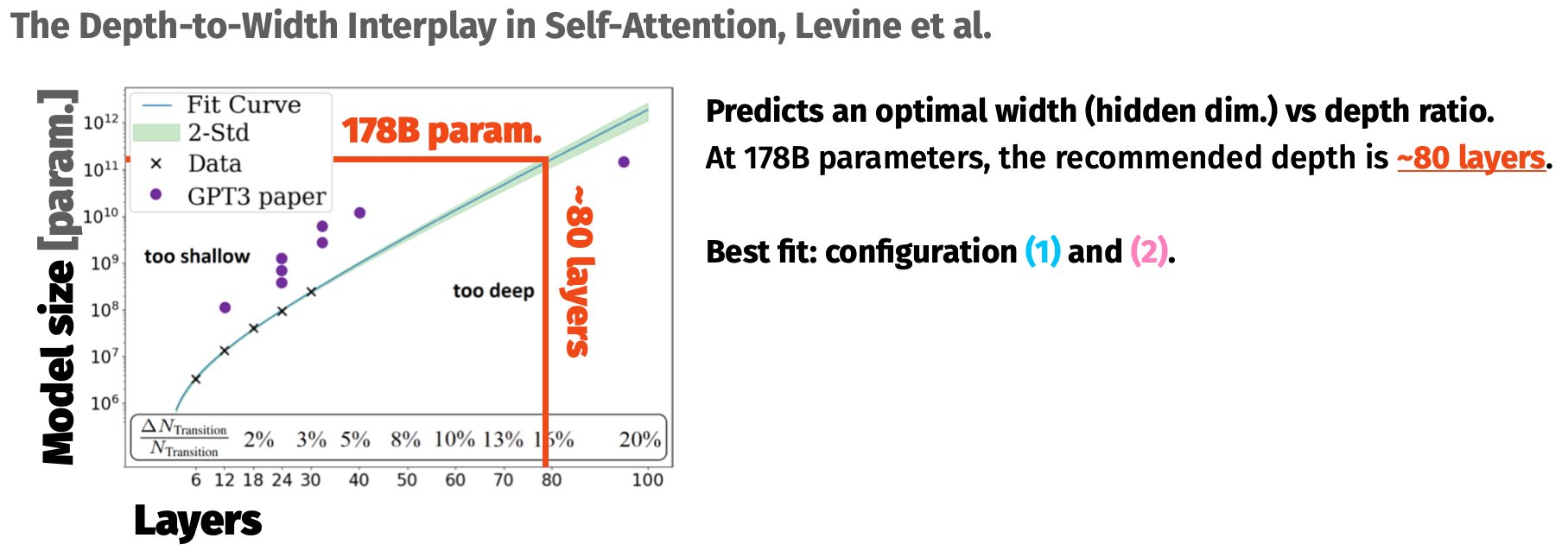
Speed matters
Finally, Stas Bekman, BigScience's engineer extraordinaire, benchmarked hundreds of configs to find the fastest one. You can read more about it in his
chronicles.
It's all about finding the right set of magic numbers, avoiding effects such as tile/wave quantisation.
We ended up with three final promising configs. We rejected (1) because of its large attention heads, and selected (3) as it was faster than (2). Speed matters: every extra bit of throughput means more total compute, thus more pretraining tokens, and a better final model.

Official launch 🚀
The training of BigScience's final 176B was was officially launched on March 11, 2022 11:42am PST on Jean Zay. If you are interested in learning more about the final model architecture, check out
this paper from the Architecture and Scaling working group of Big Science.
Credits to everyone directly involved in shaping the final model: Teven Le Scao, Thomas Wang, Daniel Hesslow, Iz Beltagy, Thomas Wolf, Stas Bekman. And more broadly, thanks to everyone involved in BigScience for making this possible!
