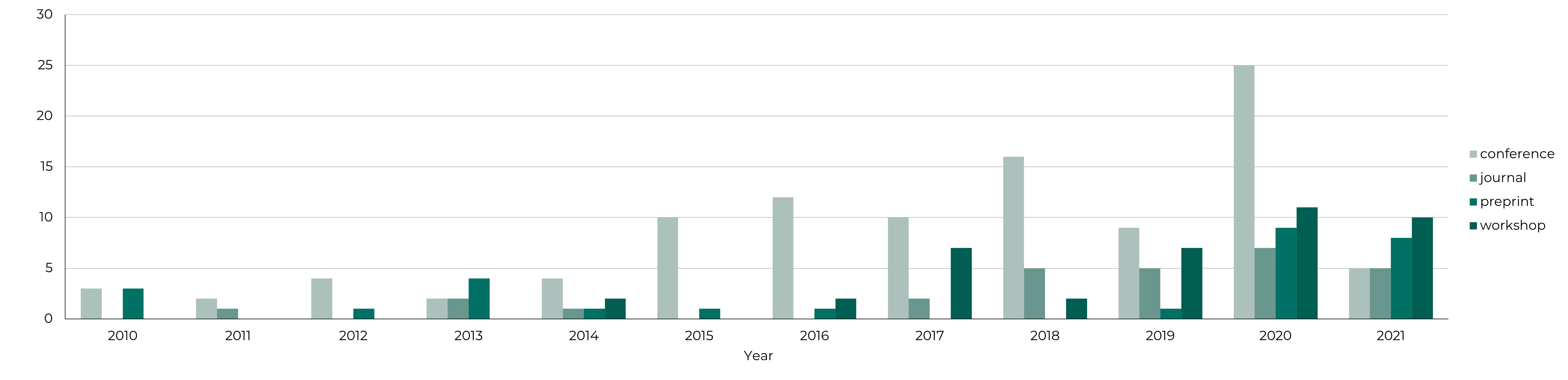Masader aims at increasing the discoverability of Arabic NLP
datasets and helping researchers identify the most suitable dataset for their research
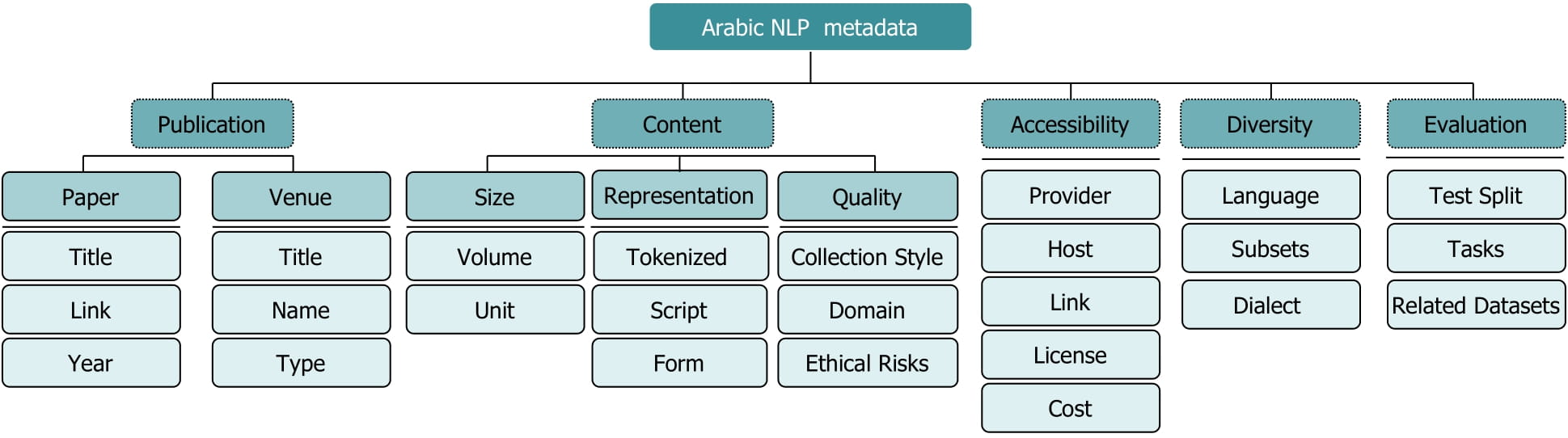
questions. In this research we collected more than 200 datasets and manually annotated
them with 25 attributes discussing publication, content, accessibility, diversity
and evaluation.
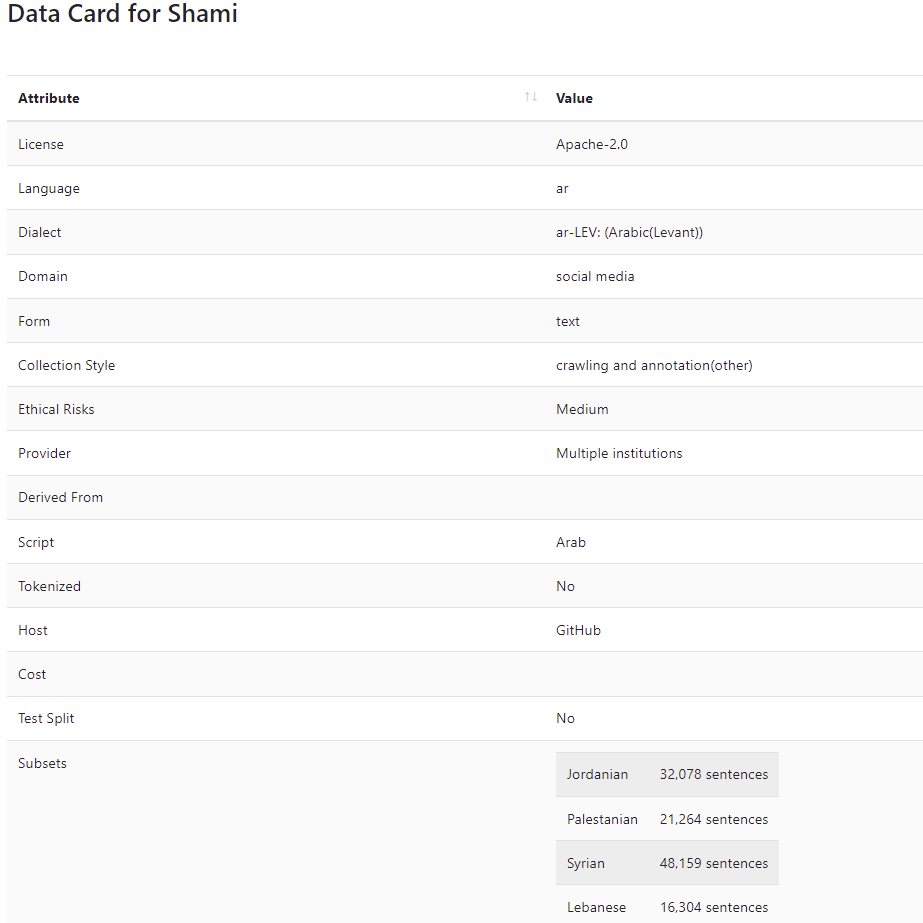
An example of such annotation is the
Shami corpus (Abu Kwaik et al., 2018) where in this example we show the metadata of the corpus.
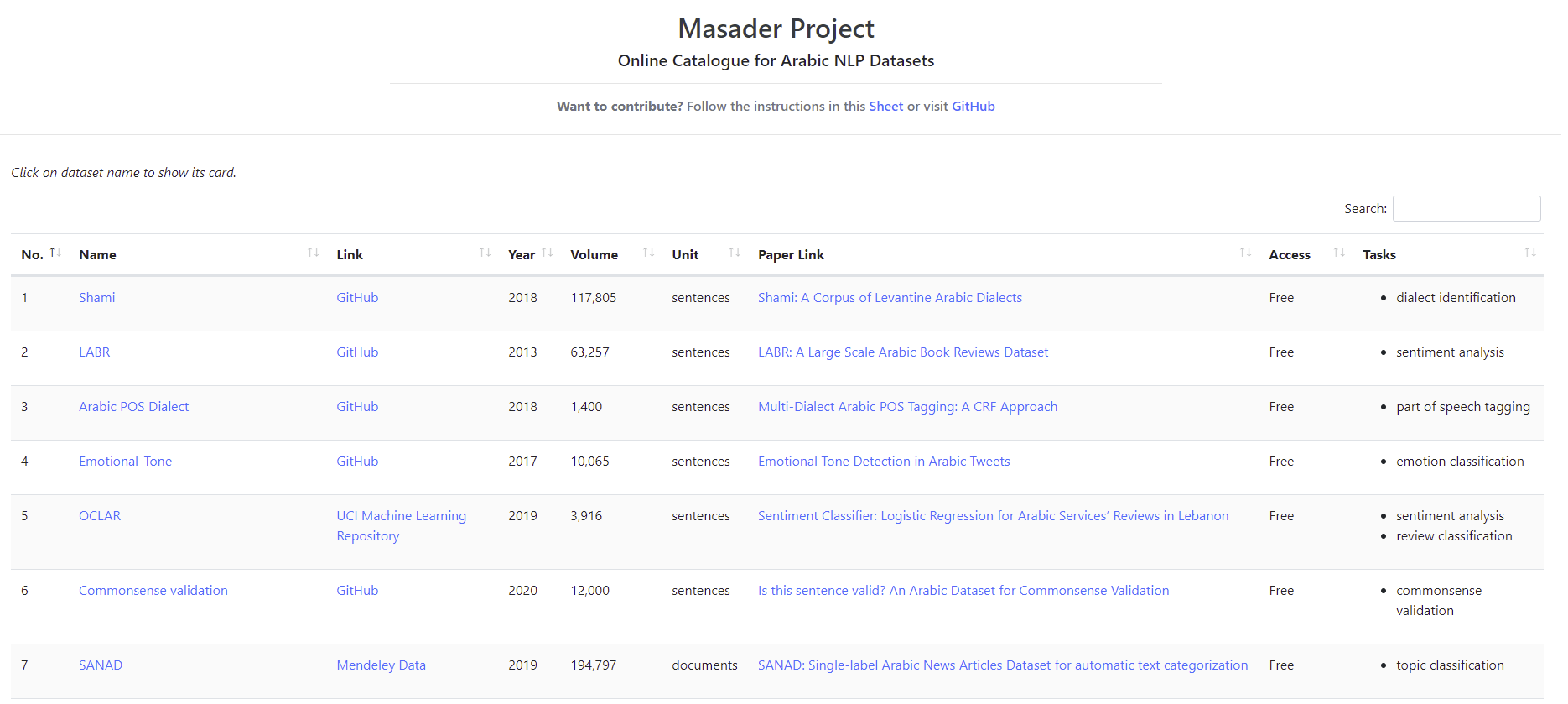
To easily navigate the collected metadata we created a website that shows the metadata in a summarised form.
Clicking on the dataset name shows more metadata about the dataset in a data card format.
Using the annotated datasets we can analyse the current status of Arabic NLP datasets, in terms of publications, as we notice a trend of publishing more datasets recently in different venues.
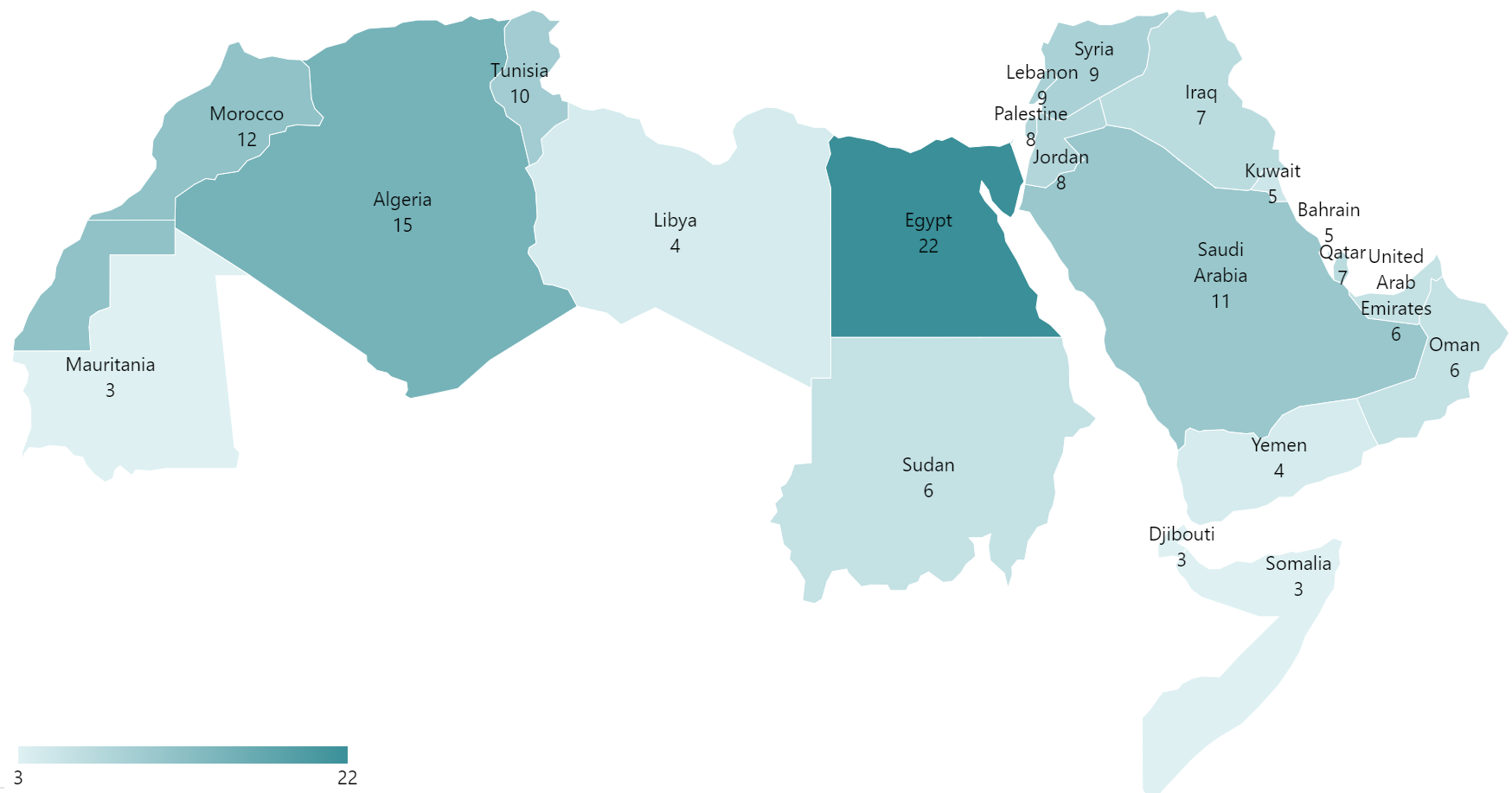
We also observe the dialect diversity of published datasets across the middle east and north Africa regions as more datasets are tackling low-resource dialects.
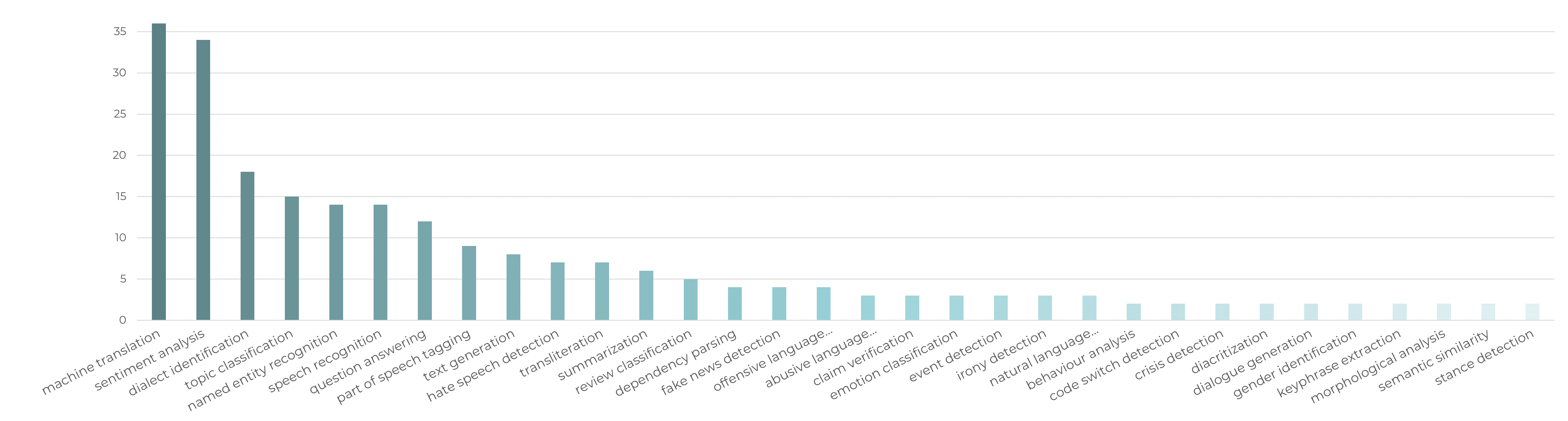
We also summarise the most used tasks in the published datasets with machine translation and sentiment analysis being the top two.
While this research provides a comprehensive analysis, it is only a snapshot in time and extra efforts are required to drive the field more in that direction. As a future work, we plan to keep the catalogue updated by adding new datasets and also support community-based contributions where authors can submit the metadata of their datasets to our online catalogue.