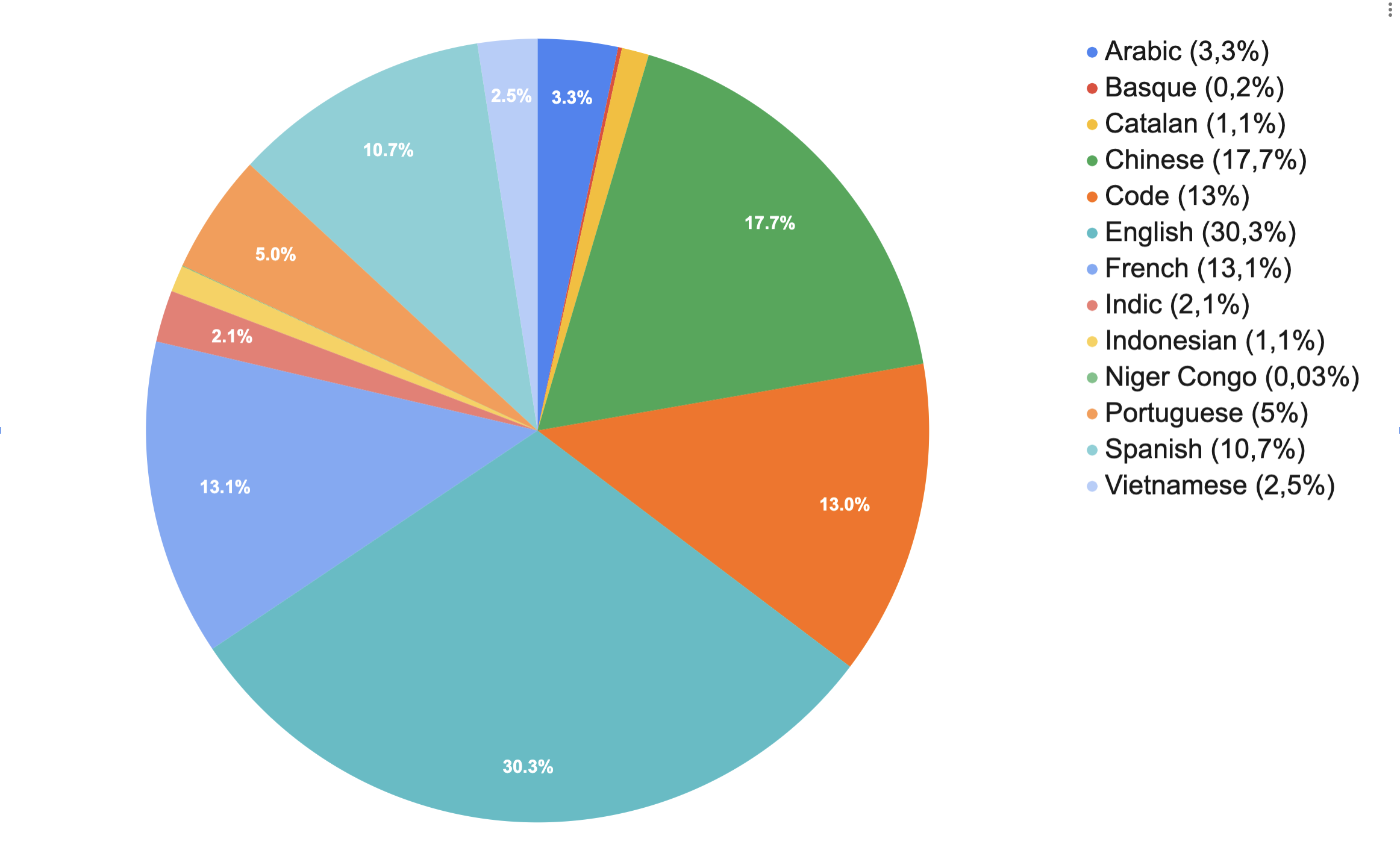
From the start of the project, the data work within BigScience
has been driven by two main categories of considerations:
Approaching data curation, collection, and management more
responsibly to meet these high-level categories of requirements took a significant amount
of work from several working groups across the overall project:
Additionally to the diversity of aspects of the data work
(taken into account for responsible data management), the challenge of combining
these two aspects without sacrificing one for the other is also exacerbated by the
staggering amount of data required to take advantage of the proposed model size fully.
Given the targeted model size and amount of computation the Jean Zay computer provided, this
amount was estimated to be upward of 350 billion tokens. For a sense of scale: if we were to
print it on A4 paper and stack it up, we’d get about
141 Eiffel towers, 5 Mount Everests,
or 1/1000th of the distance to the Moon (or 1.7 times the circumference of the Large Hadron
Collider)!
This unprecedented scale makes it nearly impossible to fully evaluate the impact of any
automatic curation choices on the whole corpus. It is also challenging to gain good insights
by manually inspecting data samples. To address these challenges and to foster intelligibility
and accountability of the curation process, we then prioritized the following approaches in our work:
- Tools to support human decisions at scale over full automation. A significant part of our
curation effort went into developing tools to help find a middle ground between these two paradigms,
allowing participants to better collaborate on curation decisions at the right granularity level to combine different
data quality notions.
- Fewer languages, more language expertise.Using the tools described above properly still
requires an understanding of the contexts we want to apply them to and having both a dedicated
effort and fluent speakers for each of the considered languages in the project. As a result,
we decided to focus our effort on languages and language groups to which we could commit sufficient resources
(as pictured above).
The remainder of this blog post specifically describes the efforts of our
data preparation task force between December 2021 and the start of the training on March 11th,
2022 to implement these strategies, leverage all of thise scholarship outlined above, and identify and address additional concerns
to build the actual training corpus.
Making the Language Modeling Dataset

Starting from January 2022, a dedicated sprint with +15 researchers was
initiated to retrieve the data, including the ones sourced by the working groups, process it,
and build the training dataset.
The data came from three sources:
- The Data Sourcing Catalog included many primary data sources and existing NLP
datasets participants wanted to have in our training corpus.
- Additional targeted websites identified by members of the Data Sourcing group as
representative of a diversity of geographical language varieties, obtained through a
pseudo crawl (i.e., by finding their data in an existing web crawl).
- We also extracted data in our target languages from the OSCAR v2 web crawl
dataset based on several language-specific data quality measures.
For all three components,
- We first retrieved the source data,
- Then we applied various pre-processing steps based on the
data kind and some visualization and indicators of data quality,
- Finally, we extracted the pre-processed text that would go to training the
model as ready-to-load datasets in the Hugging Face Hub before the training started.
Filters, tools, and indicators of data quality
Our filtering process's goal and main selection criterion were
to expose the model to
text humans wrote for humans. To guide our curation effort
to that end, we found it helpful to compute aggregated statistics for each data source,
such as:
- Documents with a very high ratio of special characters (mostly punctuation)
were found to often correspond to failures of the retrieval or upstream pre-processing system
(e.g., when ill-formed HTML code leaks through in a text extraction pipeline)
- We expect specific categories of common tokenswords (known as closed class words)
to appear in a specific frequency in any natural language document. Documents with
a low common tokenclosed class word ratio tended to correspond to tables, lists, or
other documents with unexpected formatting. The relevant lists of common tokenslosed
class words were initialized from part-of-speech data and validated by fluent language
speakers.
- We also found the language identification confidence score for high-resource languages
to be a useful general indicator of whether the text corresponds
to natural language, with low scores usually reaching pre-processing or retrieval failures.
- Other similar indicators included word repetition statistics, sequence length, perplexity,
and flagged words in various languages.
At a minimum, the indicators above helped surface data sources
that warranted additional attention and pre-processing before using them. In some cases,
we also used some of these metrics to automatically filter data items in a data source
after manually examining the impact of the filtering. The following sections describe these processes in more detail.
Preparing the Catalog and Pseudo-Crawl Sources
We treated data sources from both the Catalog and Pseudo-Crawl
similarly as they had all been manually selected by participants, with a combination
of manual and automatic curation:
We retrieved the Data Catalog entries during a collaborative event in December,
where the participants’ main goal was to obtain the source data to be processed later.
The process for retrieving the pseudo-crawl data was a bit more involved. We queried an
index over two years’ worth of CommonCrawl dumps to find pages from the target websites,
then extracted the corresponding file positions in a CommonCrawl WARC dump and ran a text extraction pipeline.
We then applied the following steps:
- We performed document-level and page-level deduplication in the catalog and
pseudo-crawl, respectively, to remove repeated instances of the same item in a single source.
We also used information from the page URLs in the pseudo-crawl to further deduplicate the data.
- We examined data sources that triggered the indicators described above to see which
ones may need further processing and devised heuristics that made the text more human-readable.
One such heuristic applied to all pseudo-crawl websites, and some catalog sources consisted of
removing lines that occurred in too many documents across a source. We found that those often
corresponded to menu items or boilerplate content.
- To favor learning from more extended contexts, we filtered out catalog items
that were too short for higher-resource languages. We will concatenate more concise disjoint
examples for lower-resource languages when they occur.
- Finally, we automatically filtered out pages from the pseudo crawl data based on the
values of some of the indicators described above:
length, character repetitions, language ID confidence, and closed class word ratios.
OSCAR Filtering and Processing
After processing the first two categories of data, we obtained a
little over 850GB of processed text out of the 1.5TB we estimated the model could learn
from, given our proposed model size and computational budget. Since other efforts of a
similar scale have drawn most or all of their training data from web crawls, using a
similar approach to make up the remaining part of the corpus struck us as both a good
way to make results easier to compare, and hopefully to expose the model to text and
document structures that were still not covered after our extensive cataloging effort.
We also wanted to ensure that our web crawl curation process would learn from previous
successes and failures (and ensuing criticisms). We describe our efforts to that end next.
The high-level approach was the following:
- Obtain a full version of the OSCARv2 dataset.
- Extract the data corresponding to 13 languages for which we were reasonably confident in
the precision of the language identification system (Arabic, Basque, Catalan, Chinese, English,
French, Indonesian, Portuguese, Spanish, Vietnamese, Bengali, Hindi, Urdu).
- Establish a clear objective for the outcome of a page-level filtering process:
we wanted to keep pages where most of the content was written by humans for humans
(removing menu pages, pages with mostly code, “spam” or bot-generated pages, etc.)
- Define a set of page-level metrics that could help us identify pages that fell
outside of this curation goal. Some of these metrics, such as character n-gram repetition
or particular token incidence, were computed the same way across languages. Others, such as
closed class word ratios or flagged words, had language-specific parameters provided by fluent
speakers.
- We created a tool to visualize the distribution of these metric values on samples of
OSCAR pages in each of the languages and to check their values on specific inputs. This
tool was used to help native language speakers set thresholds for each of these metrics
that would allow us to filter the OSCAR dataset down to our target (human-readable text
written by humans) while minimizing false positives of the exclusion process (i.e., asking
participants to prioritize precision over recall and checking the behavior on high-stake
suspected false positives to minimize disparate impacts).
- After applying the filtering described above, we ran a deduplication step to remove
repeated pages.
- Finally, we identified some categories of Personal Information (also known as
Privately Identifying Information, PII) which we could automatically find in text
with good precision (including user IDs, emails, or IP addresses), and redacted them
from the text (by replacing them with special tokens such as PI: EMAIL).
The outcome of this approach consisted of language-specific OSCAR data ranging from
1 to 150GB for most languages and over 1.1TB for English. We added all of the former data
to the training corpus and randomly sub-sampled 100GB of the English portion. In the end,
OSCAR data made up about 40% of the final training corpus.
Concluding Remarks and Next Steps
In this post, we have described our efforts to build a
large multilingual corpus guided by the following goals and values:
- Target diversity of content types and geographical diversity of sources
- Prioritize human input and expertise in the curation process to foster data quality
and accountability of the curation decisions
- Build a corpus of a size that will allow us to make full use of our computation budget
- Select, process, and document data sources to enable better data governance.
Dataset Release and Documentation Plans
The efforts of the past months were chiefly focused on preparing the aggregated training
corpus in time for the training run while ensuring that the process was documented well
enough to enable us later to provide complete documentation and partial release of the
individual data sources. The next few months will be focused on leveraging this work to
incrementally release either an extensive visualization or the full content of the sources
according to the recommendations of our Data Governance work:
- Most of the data sources are deemed ready to be fully released. We will work on finalizing
their processing and documentation throughout the model training and release them under the
care of BigScience organization of the Hugging Face hub.
- Some of the data sources were entrusted to us for the explicit purpose of training the
BigScience model but needed further efforts to be made more publicly available. We will keep
working on the governance structure we proposed to make progress towards their release.
In particular, we are looking for organizations who want to act as data hosts for these sources;
reach out if your organization would be a good candidate!
- A few of the sources we were able to use for training cannot be fully released,
either for privacy or for licensing reasons. For these, we are working on finalizing
documentation and proposing interactive visualizations for researchers who want to interrogate
the full training corpus.
Stay tuned for updates on each of these aspects in the coming months!
Annexe
List of 46 languages
Niger-Congo languages:
- Chi Tumbuka (0.00002%)
- Kikuyu (0.00004%)
- Bambara (0.00004%)
- Akan (0.00007%)
- Xitsonga (0.00007%)
- Sesotho (0.00007%)
- Chi Chewa (0.0001%)
- Twi (0.0001%)
- Setswana (0.0002%)
- Lingala (0.0002%)
- Northern Sotho (0.0002%)
- Fon (0.0002%)
- Kirundi (0.0003%)
- Wolof (0.0004%)
- Luganda (0.0004%)
- Chi Shona (0.001%)
- Isi Zulu (0.001%)
- Igbo (0.001%)
- Xhosa (0.001%)
- Kinyarwanda (0.003%)
- Yoruba (0.006%)
- Swahili (0.02%)
Indic languages:
- Assamese (0.01%)
- Odia (0.04%)
- Gujarati (0.04%)
- Marathi (0.05%)
- Punjabi (0.05%)
- Kannada (0.06%)
- Nepali (0.07%)
- Telugu (0.09%)
- Malayalam (0.1%)
- Urdu (0.1%)
- Tamil (0.2%)
- Bengali (0.5%)
- Hindi (0.7%)
Other languages:
- Basque (0.2%)
- Indonesian (1.1%)
- Catalan (1.1%)
- Vietnamese (2.5%)
- Arabic (3.3%)
- Portuguese (5%)
- Spanish (10.7%)
- Code (13%)
- French (13.1%)
- Chinese (17.7%)
- English (30.3%)